3.01 Minds That Speak, Hearts That Listen: Subreddit NLP
Written on June 12th, 2022 by Sb Fuller
Research campuses experience departmental isolation. Unfortunately, many research breakthroughs come about through collaboration and interdepartmental discourse, which is largely hampered by the separation of different disciplines.
Interdepartmental discourse can happen in public through publications and conferences, but most discourse occurs in private and in less polished public friendly formats. A lot of this private correspondance happens through private institutional channels and therefore could be useful to the greater research institute at large for better understanding of inderdepartmental research.
Better auto-categorization of passive interdepartmental discourse could accelerate the occurance of collaborative breakthroughs most important to research and the development of knowledge.
Furthermore, many researchers determine the key words for their own research but often have blind spots about the applicability of their work to other disciplines. Better auto-categorization could give us clues about intersecting interest and could aid in the encouragement of better environments of collaboration.
This investigation here asks, can a community text bank like reddit be used to create a model for differentiating disciplines from each other? Can this investigation reveal key words that exist at the overlap and extremities of these disciplines?
Analysis and Modeling:
Using an API, thousands of posts were scraped from two subreddits, r/Cardiology and r/neuroscience. Text from the posts and post titles were organized, cleaned, and vectorized. The subsequent word counts were used to build a better understanding of the intersections and extremities of these communities. Neuroscience posts and titles appear to be slightly longer on average than those from the Cardiology subreddit, but not significantly so.
The following plots come from a larger scattertext plot showing frequency and overlap of many terms from the combined text landscape of both subreddits. Words in top right corner are those very common in both subreddits (e.g. ‘research’, ‘help’,’advice’, etc.), while words approaching the bottom left corner are those that are most rare but equally present in both subreddits (e.g. ‘ai’, ‘fear’, ‘podcast’, ‘spike’, etc.). This larger plot exists as an interactive html file in main GitHub repository.


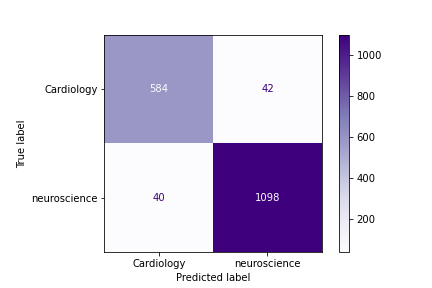
After a slight tweak to the first ensemble model, the confusion matrix below was produced to show the performance of the improved best performing model. This model is a count vectorized voting classified model consisting of unevenly weighted logistic regression, random forest, and naive bayes estimators. This ensemble model is the best performing model in terms of classifying which subreddit any given post comes from.tn_05
Conclusion:
Subreddits, as initial sources of community language, prove to be exceptionally strong source datasets for creating models that accurately predict and classify research community discourse. These models, in combination with others built from internal institutional source text could be used to auto-categorize internal correspondance.
Misclassification seem to occur because post content has nothing to do with either neuroscience or cardiology (e.g. “hello”), because a strong word of one discipline outweighs a weaker word from another (e.g. “blood” is stronger than “mri”), or because the only keywords a post contains are words that are heavily used by both communities (e.g. “stroke”, “research”, etc.) It is in these middle confusion areas where the greatest potential for future classification analyis or future departmental intersectionality perhaps may be found.
Check out the interactive plot HERE.
Please feel free to find more information and code behind the project HERE.